Deficiencies of precomputed (open-loop) optimal control
In the previous section we learnt how to compute an optimal control sequence on a finite time horizon using numerical methods for solving nonlinear programs (NLP), and quadratic programs (QP) in particular. There are two major deficiencies of such approach:
The control sequence was computed under the assumption that the mathematical model is perfectly accurate. As soon as the reality deviates from the model, either because of some unmodelled dynamics or because of the presence of (external) disturbances, the performance of the system will deteriorate. We need a way to turn the presented open-loop (also feedforward) control scheme into a feedback one.
The control sequence was computed for a finite time horizon. It is commonly required to consider an infinite time horizon, which is not possible with the presented approach based on solving finite-dimensional mathematical programs.
There are several ways to address these issues. Here we introduce one of them. It is known are Model Predictive Control (MPC), also Receding Horizon Control (RHC). Some more are presented in the next two sections (one based on indirect approach, another one based on dynamic programming).
Model predictive control (MPC) as a way to turn open-loop control into feedback control
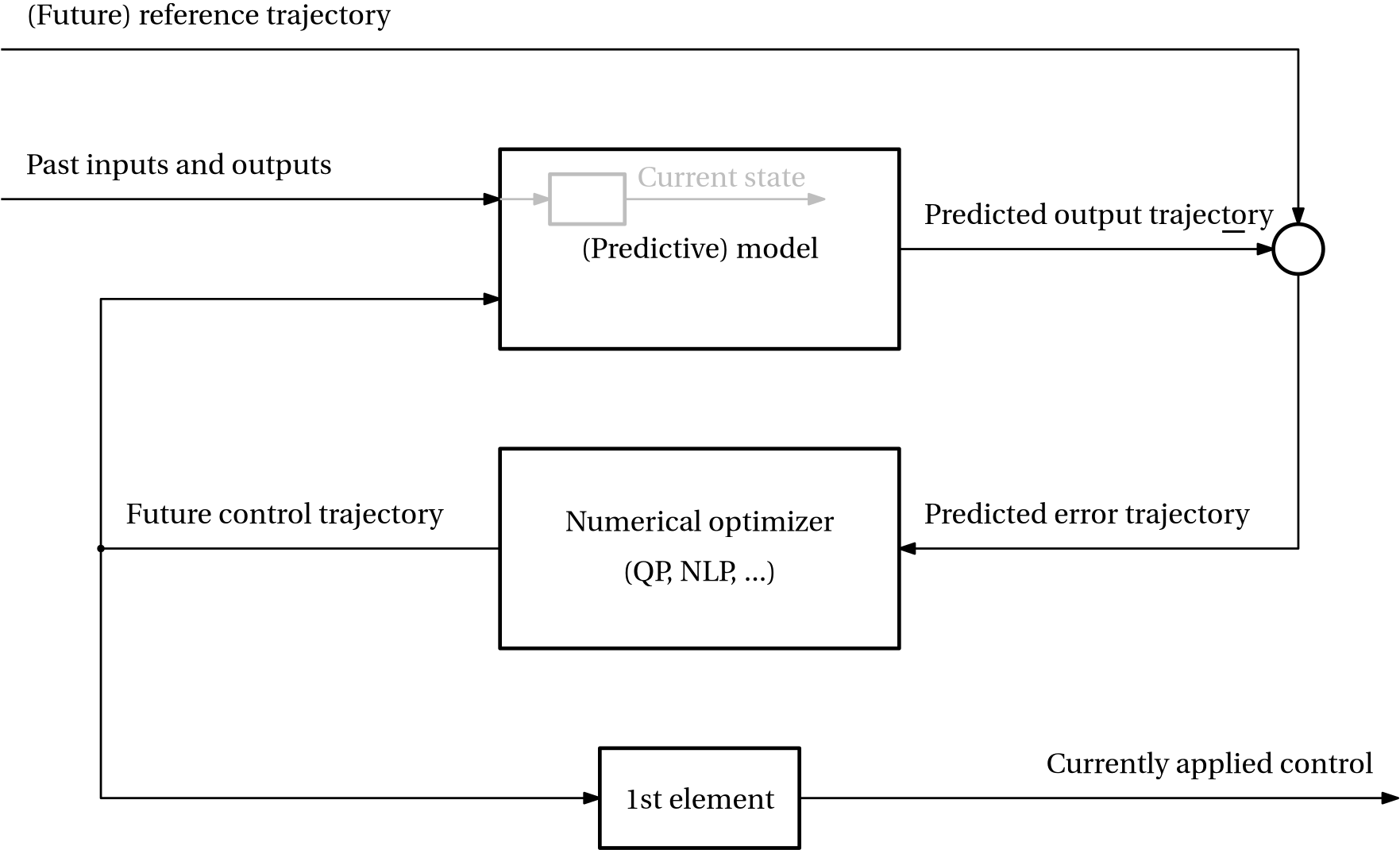
The idea is to compute an optimal control sequence on a finite time horizon using the optimization framework presented in the previous section, but then apply only the first element of the computed control trajectory to the system, and proceed to repeating the whole procedure after shifting the time horizon forward by one time step. The name “model predictive control” expresses the fact that a model-based prediction is the key component of the controller. This is expressed in Fig. 1.
Figure 1: Diagram describing a single MPC step. Recall that the information carried by the past input trajectories can compressed into the state of the system. A state observer providing an estimate of the state must then be a component of the whole MPC, but then needs not only the input but also the output trajectories.
The other name “receding horizon control” is equally descriptive, it emphasizes the phenomenon of the finite time horizon (interval, window) receding (shifting, moving, rolling) as time goes by.
NoteWe all do MPC in our everyday lives
It may take a few moments to comprehend the idea, but then it turns out perfectly natural. As a matter of fact, this is the way most of us control our lifes every day. We plan our actions on a finite time horizon, and to build this plan we use both our understanding (model) of the world and our knowledge of our current situation (state). We then execute the first action from our plan, observe the consequences of our action the and recent changes in the environment, and update our plan accordingly on a new (shifted) time horizon. We repeat this procedure over and over again. It is crucial that the prediction horizon must be long enough so that the full impact of our actions can be observed, but it must not be too long because the planning then becomes too complex and predictions unreliable.
MPC regulation
We first investigate the situation when the reference (the set-point, the required final state) is zero.
We restrict ourselves to a linear system and a quadratic cost function. We impose lower and upper bounds on the control, and optionally on the states as well. We consider a (long) time horizon N.
\begin{aligned}
\operatorname*{minimize}_{\bm u_0,\ldots, \bm u_{N-1}, \bm x_{0},\ldots, \bm x_N} &\quad \frac{1}{2} \bm x_N^\top \mathbf S \bm x_N + \frac{1}{2} \sum_{k=0}^{N-1} \left(\bm x_k^\top \mathbf Q \bm x_k + \bm u_k^\top \mathbf R \bm u_k \right)\\
\text{subject to} &\quad \bm x_{k+1} = \mathbf A\bm x_k + \mathbf B\bm u_k,\quad k = 0, \ldots, N-1, \\
&\quad \bm x_0 = \mathbf x_0,\\
&\quad \mathbf u^{\min} \leq \bm u_k \leq \mathbf u^{\max},\\
&\quad (\mathbf x^{\min} \leq \bm x_k \leq \mathbf x^{\max}).
\end{aligned}
If the time horizon is really long, we can approximate it by \infty, in which case we omit the terminal state penalty from the overall cost function
\begin{aligned}
\operatorname*{minimize}_{\bm u_0,\bm u_1,\ldots, \bm x_{0}, \bm x_1,\ldots} &\quad \frac{1}{2} \sum_{k=0}^{\infty} \left(\bm x_k^\top \mathbf Q \bm x_k + \bm u_k^\top \mathbf R \bm u_k \right)\\
\text{subject to} &\quad \bm x_{k+1} = \mathbf A\bm x_k + \mathbf B\bm u_k,\quad k = 0, 1, 2, \ldots, \\
&\quad \bm x_0 = \mathbf x_0,\\
&\quad \mathbf u^{\min} \leq \bm u_k \leq \mathbf u^{\max},\\
&\quad (\mathbf x^{\min} \leq \bm x_k \leq \mathbf x^{\max}).
\end{aligned}
Now, in a model predictive control (MPC) scheme, at the discrete time t, an LQR problem on a finite (and typically only modestly long time prediction horizon N_\mathrm{p} (typically N_\mathrm{p}\approx 20 or 30 or so) is formulated and solved. This time window then moves (recedes, rolls) either forever or untill the the final time N is reached.
Since the problem is parameterized by the “initial” time t and the state at this time, we need to reflect this in the notation. Namely, \bm x_{t+k|t} is the predicted state at time t+k as predicted at time t using the information available at that time, that is, \mathbf x_t (= \bm x_{t|t}) and the computed control trajectory up to the time just one step before t+k. We can emphasize this dependence by writing it explicitly as \bm x_{t+k|t}(\bm x_t, \bm u_{t}, \bm u_{t+1}, \ldots, \bm u_{t+k-1}), but then the notation becomes rather convoluted and so we stick to the shorter one. We emphasize that it is really just a prediction. The true state at time t+k is denoted \bm x_{t+k}. Similarly, \bm u_{t+k|t} is the future control at t+k as computed at time t using the information available at that time, that is, \bm x_t.
NoteAlternative notation for variables in MPC optimization problems
If you find the notation \bm x_{t+k|t} clumsy, feel free to replace it with something simpler that does not explicitly mention the time at which the prediction/optimization is made but does not clash with the true state at the given time. Perhaps just using a different letter with a simple lower index such as \bm z_k for the state and \bm v_k for the control, while understanding k relative with respect to the current discrete time.
The optimization problem to be solved at every discrete- time t is
\begin{aligned}
\operatorname*{minimize}_{\bm u_{t|t},u_{t+1}\ldots, \bm u_{t+N_\mathrm{p}-1}, \bm x_{t|t},\ldots, \bm x_{t+N_\mathrm{p}|t}} &\quad \frac{1}{2} \bm x_{t+N_\mathrm{p}|t}^\top \mathbf S \bm x_{t+N_\mathrm{p}|t} + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \left(\bm x_{t+k|t}^\top \mathbf Q \bm x_{t+k|t} + \bm u_{t+k|t}^\top \mathbf R \bm u_{t+k|t} \right)\\
\text{subject to} &\quad \bm x_{t+k+1|t} = \mathbf A\bm x_{t+k|t} + \mathbf B\bm u_{t+k|t},\quad k = 0, \ldots, N_\mathrm{p}-1, \\
&\quad \bm x_{t|t} = \mathbf x_t, \\
&\quad \mathbf u^{\min} \leq \bm u_{t+k|t} \leq \mathbf u^{\max},\\
&\quad \mathbf x^{\min} \leq \bm x_{t+k|t} \leq \mathbf x^{\max}.
\end{aligned}
Note that by using the upright front in \mathbf x_t we emphasize that the current state plays (measured or estimated) the role of a parameter and not an optimization variable within this optimization problem.
Example 1 (MPC) We illustrate the key ingrediences of MPC using the following example. The plant to be regulated is a second-order LTI system with one control input, parameterized by the matrices \mathbf A and \mathbf B, the latter actually a single-column matrix, with a quadratic cost parameterized by the matrices \mathbf Q and \mathbf R, the latter actually a scalar, and with constraint control. The prediction horizon is set to 5.
Show the code
usingOSQPusingJuMPusingLinearAlgebrarhocp =Model(OSQP.Optimizer) # Defining the receding-horizon (RH) optimal control problem (OCP).set_silent(rhocp)# System dynamics x(k+1) = A*x(k) + B*u(k):A = [6/56/5; -1/26/5]B = [1; 1/2]N_full =30# Total simulation length.N =5# Prediction horizon length.h =1.0# Sampling time.x_init = [3.0, 3.0] # Initial state.# Quadratic cost function weights:Q =Diagonal([1.0, 1.0])R =5.0# Input constraints:u_min =-3.0u_max =3.0n =size(A,1) # Order of the system.# Building the optimization model for the receding-horizon optimal control problem RH-OCP:@variable(rhocp, x[1:n, 1:N+1]) # State trajectory over the prediction horizon.@variable(rhocp, u_min <= u[1:N] <= u_max) # Control trajectory over the prediction horizon.@constraint(rhocp, [i=1:N], x[:,i+1] == A*x[:,i] + B*u[i])fix(x[1,1], x_init[1])fix(x[2,1], x_init[2])@objective(rhocp, Min, sum(x[:,i]'*Q*x[:,i] + R*u[i]^2 for i=1:N) + x[:,N+1]'*Q*x[:,N+1])# Function that solves the RH OCP for the current state xₖ at time step k:functionmpc_regulation(rhocp, xₖ, k, N) fix(x[1,1], xₖ[1])fix(x[2,1], xₖ[2]) optimize!(rhocp)returnvalue.(u), value.(x)end# Receding-horizon simulation:x_opt_full = [x_init,]u_opt_full =Float64[]x_pred_full =Vector{Matrix{Float64}}()u_pred_full =Vector{Vector{Float64}}()for k in1:(N_full-N) # Receding-horizon simulation loop. xₖ = x_opt_full[end] # Current state. u_pred, x_pred =mpc_regulation(rhocp, xₖ, k, N) # Optimal control sequence over the prediction horizon. uₖ = u_pred[1] # Apply only the first control input. x⁺ = x_pred[:,2] # Next state from the predicted trajectory.#x⁺ = x_pred[:,2] + randn(2)*0.1 # True next state differs from the predicted trajectory due to the disturbance.push!(x_opt_full, x⁺)push!(u_opt_full, uₖ)push!(x_pred_full, x_pred)push!(u_pred_full, u_pred)end
Figure 2: Evolution of the state of a system from some nonzero initial state towards zero state using an MPC. The blue trajectory is the actual state trajectory as realized by the receding-horizon control, the gray trajectories are the predicted trajectories as computed at every time step. The length of the prediction horizon set to 5.
Figure 3: Evolution of the state variables and control input of a system from some nonzero initial state towards zero state using an MPC. The blue markers are the actual state and control trajectories as realized by the receding-horizon control, the gray markers are the predicted trajectories as computed at every time step. The length of the prediction horizon set to 5.
Previously we have learnt how to rewrite this finite-horizon optimal control problem as a QP problem, which can then be solved with a dedicated QP solver. However, it is worth analyzing the case without the inequality constraints. We know that we can formulate a system of linear equations and solvem, which we formally write at
\begin{bmatrix} \bm u_{t|t} \\ \bm u_{t+1|t} \\ \vdots \\ \bm u_{t+N-1|t} \end{bmatrix}
=
\mathbf{H}^{-1} \mathbf{F} \mathbf x_t,
but since we only indend to apply the first element of the control trajectory, we can write
\bm u_{t|t}
=
\underbrace{\begin{bmatrix} \mathbf I & \mathbf 0 & \mathbf 0 & \ldots & \mathbf 0 \end{bmatrix}
\mathbf{H}^{-1} \mathbf{F}}_{\mathbf K_t} \mathbf x_t,
in which we can recognize the classical state feedback with the (time-varying) gain \mathbf K_t. This is a very useful observation – the MPC strategy, when not considering inequality constraints (aka bounds) on the control or state variables, is just a time-varying state feedback. This observation will turn crucial in later chapters when we come back to MPC and analyze its stability.
MPC tracking
(Nonzero) state reference tracking
An immediate extension of the regulation problem is that we replace the desired target (reference) state \mathbf x^\mathrm{ref} = \mathbf 0 with some nonzero \mathbf x^\mathrm{ref} \neq \mathbf 0. The cost function then changes to
\begin{aligned}
J(\ldots) &= \frac{1}{2} (\bm x_{t+N_\mathrm{p}|t}-{\color{blue}\mathbf x^\mathrm{ref}})^\top \mathbf S \, (\bm x_{t+N_\mathrm{p}|t}-{\color{blue}\mathbf x^\mathrm{ref}})\\
& \qquad + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \left((\bm x_{t+k|t}-{\color{blue}\mathbf x^\mathrm{ref}})^\top \mathbf Q \, (\bm x_{t+k|t}-{\color{blue}\mathbf x^\mathrm{ref}}) + \bm u_{t+k|t}^\top \mathbf R \bm u_{t+k|t}\right).
\end{aligned}
It seems that we are done, that the only change that had to be made was replacement of the predicted state by the prediction of tracking error in the cost function. But not so fast! Recall that unless the nonzero reference state qualifies as an equilibrium, the control needed to keep the system at the corresponding state is nonzero. Namely, for a general discrete-time linear system \bm x_{k+1} = \mathbf A \bm x_k + \mathbf B \bm u_k, at an equilibrium (a steady state) \mathbf x^\mathrm{ss}, the following must be satisfied by definition
\bm x^\mathrm{ss} = \mathbf A \bm x^\mathrm{ss} + \mathbf B \bm u^\mathrm{ss}.
Rewriting this, we get
(\mathbf A - \mathbf I) \bm x^\mathrm{ss} + \mathbf B \bm u^\mathrm{ss} = \mathbf 0.
Fixing the value of the steady state vector \bm x^\mathrm{ss} to \mathbf x^\mathrm{ref}, we see that \bm u^\mathrm{ss} = \mathbf 0 if (\mathbf A - \mathbf I) \bm x^\mathrm{ref}, that is, if the desired steady state \bm x^\mathrm{ref} is in the null space of (\mathbf A - \mathbf I). If the desired steady state does not satisfy the condition, which will generally be the case, the corresponding control is necessarily nonzero. It then it makes no sense to penalize the control itself. Instead, its deviation from the compatible nonzero value should be penalized. As a consequence, the cost function should be modified to
\begin{aligned}
J(\ldots) &= \frac{1}{2} (\bm x_{t+N_\mathrm{p}|t}-{\color{blue}\mathbf x^\mathrm{ref}})^\top \mathbf S \, (\bm x_{t+N_\mathrm{p}|t}-{\color{blue}\mathbf x^\mathrm{ref}})\\
& \qquad + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \left((\bm x_{t+k|t}-{\color{blue}\mathbf x^\mathrm{ref}})^\top \mathbf Q \, (\bm x_{t+k|t}-{\color{blue}\mathbf x^\mathrm{ref}}) + (\bm u_{t+k|t}-{\color{red}\bm u^\mathrm{ss}})^\top \mathbf R (\bm u_{t+k|t}-{\color{red}\bm u^\mathrm{ss}})\right),
\end{aligned}
in which we regard {\color{blue}\mathbf x^\mathrm{ref}} as an input to the optimal control problem, and {\color{ss}\bm u^\mathrm{ss}} is a new unknown.
The optimization problem to be solved at every discrete- time t is then
\begin{aligned}
\operatorname*{minimize}_{\bm u_{t|t},u_{t+1}\ldots, \bm u_{t+N_\mathrm{p}-1}, \bm x_{t|t},\ldots, \bm x_{t+N_\mathrm{p}|t}, {\color{red}\bm u^\mathrm{ss}}} &\quad \frac{1}{2} (\bm x_{t+N_\mathrm{p}|t}-{\color{blue}\mathbf x^\mathrm{ref}})^\top \mathbf S \, (\bm x_{t+N_\mathrm{p}|t}-{\color{blue}\mathbf x^\mathrm{ref}})\\
& \qquad + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \left((\bm x_{t+k|t}-{\color{blue}\mathbf x^\mathrm{ref}})^\top \mathbf Q \, (\bm x_{t+k|t}-{\color{blue}\mathbf x^\mathrm{ref}}) + (\bm u_{t+k|t}-{\color{red}\bm u^\mathrm{ss}})^\top \mathbf R (\bm u_{t+k|t}-{\color{red}\bm u^\mathrm{ss}})\right)\\
\text{subject to} &\quad \bm x_{t+k+1|t} = \mathbf A\bm x_{t+k|t} + \mathbf B\bm u_{t+k|t},\quad k = 0, \ldots, N_\mathrm{p}-1, \\
&\quad \bm x_{t|t} = \mathbf x_t, \\
&\quad \mathbf B {\color{red}\bm u^\mathrm{ss}} = (\mathbf I-\mathbf A) {\color{blue}\mathbf x^\mathrm{ref}},\\
&\quad \mathbf u^{\min} \leq \bm u_{t+k|t} \leq \mathbf u^{\max},\\
&\quad \mathbf x^{\min} \leq \bm x_{t+k|t} \leq \mathbf x^{\max}.
\end{aligned}
Note that compared to the regulation problem, here the optimization problem contains a new (vector) optimization variable \bm u^\mathrm{ss}, and a new system of linear equations.
Output reference tracking
Oftentimes we do not have reference values for all the state variables but only for the output variables. These are given by the output equation
\bm y_k = \mathbf C \bm x_k + \mathbf D \bm u_k.
For notational convenience we restrict ourselves to the case of no feedthrough, that is, \mathbf D = \mathbf 0.
The goal for the controller is then to make the difference between \bm y_k = \mathbf C \bm x_k and \mathbf y^\mathrm{ref} (often named just \mathbf r if it is clear from the context the reference value of which variables it represents) go to zero.
Similarly as in the case of (nonzero) reference state tracking, nonzero control \bm u^\mathrm{ss} must be expected in steady state.
Note, however, that the steady state \bm x^\mathrm{ss} is not provided this time – we must relate it to the provided reference output. But it is straightforward:
\mathbf y^\mathrm{ref} = \mathbf C \bm x^\mathrm{ss}\qquad\qquad (\text{or}\; \mathbf y^\mathrm{ref} = \mathbf C \bm x^\mathrm{ss} + \mathbf D \bm u^\mathrm{ss}\; \text{in general}).
Now we have all that is needed to formulate the MPC problem for output reference tracking:
The tricky part is the terminal term in the cost function. Note that if we consider a nonzero \mathbf D matrix, the cost function is
\begin{aligned}
J(\ldots) &= \xcancel{\frac{1}{2} (\bm y_{t+N_\mathrm{p}|t}-{\color{green}\mathbf y^\mathrm{ref}})^\top \mathbf S \, (\bm y_{t+N_\mathrm{p}|t}-{\color{green}\mathbf y^\mathrm{ref}})}\\
& \qquad + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \left((\bm y_{t+k|t}-{\color{green}\mathbf y^\mathrm{ref}})^\top \mathbf Q \, (\bm y_{t+k|t}-{\color{green}\mathbf y^\mathrm{ref}}) + (\bm u_{t+k|t}-{\color{red}\bm u^\mathrm{ss}})^\top \mathbf R (\bm u_{t+k|t}-{\color{red}\bm u^\mathrm{ss}})\right),
\end{aligned}
but the trouble is that we only consider \bm u_{t+k|t} for k = 0, \ldots, N_\mathrm{p}-1, and therefore \bm y_{t+N_\mathrm{p}-1|t} is the last available predicted output – it does not provide \bm y_{t+N_\mathrm{p}|t}. The terminal penalty must then be omitted from the cost function, which we have already indicated in the formula by crossing it out.
Penalizing the control increments
There is an alternative way how to handle the need to consider a nonzero control at steady state. We can penalize not the control itself but its change, its increment
\Delta \bm u_{t+k|t} = \bm u_{t+k|t} - \bm u_{t+k-1|t}.
The rationale behind this is that once at steady state, the control does not change any longer.
But then if \Delta \bm u_{t+k|t} is the new optimization variable that replaces \bm u_{t+k|t} in the cost function, we must still be able to express the control \bm u_{t+k|t}
\bm u_{t+k|t} = \bm u_{t+k-1|t} + \Delta \bm u_{t+k|t},
for which we need to keep track of the control at the previous time step. This can be done systematically just by augmenting the state model with an auxillary state variable \bm x_{t+k|t}^\mathrm{u} \coloneqq \bm u_{t+k-1|t}
\begin{bmatrix} \bm x_{t+k+1|t} \\ \bm x_{t+k+1|t}^\mathrm{u} \end{bmatrix} = \underbrace{\begin{bmatrix} \mathbf A & \mathbf B \\ \mathbf 0 & \mathbf I \end{bmatrix}}_{\mathbf{\widetilde{A}}} \underbrace{\begin{bmatrix} \bm x_{t+k|t} \\ \bm x_{t+k|t}^\mathrm{u} \end{bmatrix}}_{\tilde{\bm{x}}_{t+k|t}} + \underbrace{\begin{bmatrix} \mathbf B \\ \mathbf I \end{bmatrix}}_{\mathbf{\widetilde{B}}} \Delta \bm u_{t+k|t}.
With this new augmented state vector, the output is
\bm y_{t+k|t} = \underbrace{\begin{bmatrix} \mathbf C & \mathbf 0 \end{bmatrix}}_{\mathbf{\widetilde{C}}} \begin{bmatrix} \bm x_{t+k|t} \\ \bm x_{t+k|t}^\mathrm{u} \end{bmatrix}.
With this new system we can now proceed to formulate the MPC tracking problem
\begin{aligned}
\operatorname*{minimize}_{\Delta \bm u_{t|t},\Delta u_{t+1}\ldots, \Delta \bm u_{t+N_\mathrm{p}-1}, \bm x_{t|t},\ldots, \bm x_{t+N_\mathrm{p}|t}} &\quad \frac{1}{2} (\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+N_\mathrm{p}|t} - \mathbf y^\mathrm{ref})^\top \mathbf S \, (\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+N_\mathrm{p}|t} - \mathbf y^\mathrm{ref}) \\
&\qquad + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \left((\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+k|t} - \mathbf y^\mathrm{ref})^\top \mathbf Q \, (\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+k|t} - \mathbf y^\mathrm{ref}) + \Delta \bm u_{t+k|t}^\top \mathbf R \, \Delta \bm u_{t+k|t} \right)\\
\text{subject to} &\quad \tilde{\bm{x}}_{t+k+1|t} = \mathbf{\widetilde{A}}\tilde{\bm{x}}_{t+k|t} + \mathbf{\widetilde{B}}\Delta \bm u_{t+k|t},\quad k = 0, \ldots, N_\mathrm{p}-1, \\
&\quad \tilde{\bm{x}}_{t|t} = \begin{bmatrix}\mathbf x_t\\ \mathbf u_{t-1}\end{bmatrix}, \\
&\quad \mathbf x^{\min} \leq \begin{bmatrix}\bm I & \mathbf 0 \end{bmatrix} \tilde{\bm x}_{t+k|t} \leq \mathbf x^{\max},\quad k = 0, \ldots, N_\mathrm{p},\\
&\quad \mathbf u^{\min} \leq \begin{bmatrix}\bm 0 & \mathbf I \end{bmatrix} \tilde{\bm x}_{t+k|t} + \Delta \bm u_{t+k|t}\leq \mathbf u^{\max},\quad k = 0, \ldots, N_\mathrm{p}-1.
\end{aligned}
A bonus of this formulation is that we can also impose contraints on \Delta \bm u_{t+k|t}, which effectively implements rate constraints on the control variables. This is useful because sometimes we want to restrict how fast the control variable (say, valve opening) changes in order to save the actuators.
Note that similarly as before, we cannot include the terminal cost if the output equation contains a feedthrough term, that is if \mathbf D\neq 0, in which case \bm u_{t+N|t} would be needed, while it is not available in our optimization problem. This does not pose a singificant trouble purely from the viewpoint of expressing the control requirements by the cost function, but we only mention in passing that it does pose a problem when it comes to guaranteeing the closed-loop stability. We postpone our discussion of closed-loop stability till later chapters, but here we only mention that the terminal penalty (on the prediction horizon), through which we penalize the deviation of the system from the desired state, is one of the mechanisms for achieving closed-loop stability. Within this \Delta \bm u framework we eliminated the need to compute the steady state \bm x^{ss}, but if stability guarantees are needed, it must be reintroduced to the problem.
#TODO Show the optimization problem including the computation of the steady state and the terminal penalty on the deviation from the steady state (even though performance-wise we are only interested in the output reference tracking).
Output reference tracking for general references (preview control)
Finally, we consider not just a single value of the output vector \mathbf y^\mathrm{ref} towards which the system should ultimately be steered, but we consider an arbitrary reference trajectory {\color{orange}\mathbf y_k^\mathrm{ref}}. The MPC problem changes (slightly) to
\begin{aligned}
\operatorname*{minimize}_{\Delta \bm u_{t|t},\Delta u_{t+1}\ldots, \Delta \bm u_{t+N_\mathrm{p}-1}, \bm x_{t|t},\ldots, \bm x_{t+N_\mathrm{p}|t}} &\quad \frac{1}{2} (\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+N_\mathrm{p}|t} - {\color{orange}\mathbf y_{t+N_\mathrm{p}}^\mathrm{ref}})^\top \mathbf S \, (\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+N_\mathrm{p}|t} - {\color{orange}\mathbf y_{t+N_\mathrm{p}}^\mathrm{ref}}) \\
&\qquad + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \left((\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+k|t} - {\color{orange}\mathbf y_{t+k}^\mathrm{ref}})^\top \mathbf Q \, (\mathbf{\widetilde{C}}\tilde{\bm{x}}_{t+k|t} - {\color{orange}\mathbf y_{t+k}^\mathrm{ref}}) + \Delta \bm u_{t+k|t}^\top \mathbf R \, \Delta \bm u_{t+k|t} \right)\\
\text{subject to} &\quad \tilde{\bm{x}}_{t+k+1|t} = \mathbf{\widetilde{A}}\tilde{\bm{x}}_{t+k|t} + \mathbf{\widetilde{B}}\Delta \bm u_{t+k|t},\quad k = 0, \ldots, N_\mathrm{p}-1, \\
&\quad \tilde{\bm{x}}_{t|t} = \begin{bmatrix}\mathbf x_t\\ \mathbf u_{t-1}\end{bmatrix}, \\
&\quad \mathbf x^{\min} \leq \begin{bmatrix}\bm I & \mathbf 0 \end{bmatrix} \tilde{\bm x}_{t+k|t} \leq \mathbf x^{\max},\quad k = 0, \ldots, N_\mathrm{p},\\
&\quad \mathbf u^{\min} \leq \begin{bmatrix}\bm 0 & \mathbf I \end{bmatrix} \tilde{\bm x}_{t+k|t} + \Delta \bm u_{t+k|t}\leq \mathbf u^{\max},\quad k = 0, \ldots, N_\mathrm{p}-1.
\end{aligned}
One last time we repeat that if a general output equation with a feedthrough term is considered, the terminal term in the cost function should be omitted.
#TODO
Hard constraints vs soft constraints on state variables
While it is fairly natural to encode the lower and upper bounds on the state variables as inequality constraints in the optimal control problem, this approach comes with a caveat – the corresponding optimization problem can be infeasible. This is a major trouble if the optimization problem is solved online (in real time), which is the case of an MPC controller. The infeasibility of the optimization problem then amounts to the controller being unable to provide its output.
For example, we may require that the error of regulating the intervehicular gap by an adaptive cruise control (ACC) system is less then 1 m. At one moment, this requirement may turn out unsatisfiable, while, say, 1.1 m error could be achievable, which would cause no harm. And yet the controller would essentially give up and produce no command to the engine. A major trouble.
An alternative is to move the requirement from the constraints to the cost function as an extra term. This way, however, the original hard constraint turns into a soft one, by which we mean that we do not guarantee that the requirement is satisfied, but we discourage the optimization algorithm from breaking it by imposing a penalty proportional to how much the constraint is exceeded.
We sketch the scheme here. For the original problem formulation with the hard constraints on the output variables
we propose the version with soft constraints
\begin{aligned}
\operatorname*{minimize}_{\bm u_1,\ldots, \bm u_{N-1}, {\color{red}\epsilon}} &\quad \sum_k^N \left[\ldots {+ \color{red}\gamma \epsilon} \right]\\
\text{subject to} &\quad \bm x_{t+k+1|t} = \mathbf A\bm x_{t+k|t} + \mathbf B\bm u_{t+k|t},\quad k = 0, \ldots, N-1, \\
&\quad \bm y_{t+k|t} = \mathbf C\bm x_{t+k|t} + \mathbf D\bm u_{t+k|t},\\
&\quad \bm x_{t|t} = \mathbf x_t,\\
&\quad \ldots \\
&\quad \mathbf y^{\min} {\color{red}- \epsilon \mathbf v} \leq \bm y_k \leq \mathbf y^{\max} {\color{red}+ \epsilon \mathbf v},
\end{aligned}
where \gamma > 0 and \mathbf v\in\mathbb R^p are fixed parameters and \epsilon is the additional optimization variable.
ImportantRequirements expressed through constraints or an extra term in the cost function
We have just encountered another instance of the classical dillema in optimization and optimal control that we have had introduced previously. Indeed, it is fairly fundamental and appears both in applications and in development of theory. Keep this degree of freeedom in mind on your optimization and optimal control journey.
Prediction horizon vs control horizon
One of the key parameters of a model predictive control is the prediction horizonN_\mathrm{p}. It must be long enough so that the key dynamics of the system has enough time to exhibit, and yet it must not be too long, because the computational load will be then too high. A rule of thumb (but certainly not a law) is N_\mathrm{p}\approx 20. There is one simple way to reduce the computational load – consider the control trajectory defined on a much shorted time horizon than the predicted state trajectory. Namely, we introduce the control horizonN_\mathrm{c} < N_\mathrm{p} (typically N_\mathrm{c} can be as small as 2 or 3 or so), and we only consider the control as optimizable on this short horizon. Of course, we must provide some values after this horizon as well (untill the end of the prediction horizon). The simplest strategy is to set it to the last value on the control horizon. The MPC problem then changes to
\begin{aligned}
\operatorname*{minimize}_{\bm u_{t|t},u_{t+1|t}\ldots, \bm u_{t+{\color{red}N_\mathrm{c}}-1|t}, \bm x_{t|t},\ldots, \bm x_{t+N_\mathrm{p}|t}} &\quad \frac{1}{2} \bm x_{t+N_\mathrm{p}|t}^\top \mathbf S \bm x_{t+N_\mathrm{p}|t} + \frac{1}{2} \sum_{k=0}^{N_\mathrm{p}-1} \bm x_{t+k|t}^\top \mathbf Q \bm x_{t+k|t} + + \frac{1}{2} \sum_{k=0}^{{\color{red}N_\mathrm{c}}-1} \bm u_{t+k|t}^\top \mathbf R \bm u_{t+k|t}\\
\text{subject to} &\quad \bm x_{t+k+1|t} = \mathbf A\bm x_{t+k|t} + \mathbf B\bm u_{t+k|t},\quad k = 0, \ldots, N_\mathrm{p}-1, \\
&\quad \bm x_{t|t} = \mathbf x_t, \\
&\quad \mathbf u^{\min} \leq \bm u_{t+k|t} \leq \mathbf u^{\max},\\
&\quad \mathbf x^{\min} \leq \bm x_{t+k|t} \leq \mathbf x^{\max},\\
&\quad {\color{red} \bm u_{t+k|t} = \bm u_{t+N_\mathrm{c}-1|t}, \quad k=N_\mathrm{c}, N_\mathrm{c}+1, \ldots, N_\mathrm{p}}.
\end{aligned}
Move blocking
Another strategy for reducing the number of control variables is known as move blocking. In this approach, the control inputs are held constant over several time steps (they are combined into blocks), effectively reducing the number of optimization variables. More on this in [1].
Open questions (for us at this moment)
Can the stability of a closed-loop system with an MPC controller be guaranteed? Even in the case of a linear system with no constraints we cannot just have a look at some poles to make a conclusion.
What is the role of the terminal state cost in the MPC problem? And how shall we choose it? Apparently, if the original time horizon is finite but very long (say, 1000), with the prediction horizon set to 20, we can hardly argue that the corresponding term in the MPC cost function expresses our requirements on the behaviour of the system at time 1000. Even less so if the original problem consider and infinite time horizon.
We are going to come back to these after we investigate the other two approaches to discrete-time optimal control – the indirect approach and the dynamical programming.
R. Cagienard, P. Grieder, E. C. Kerrigan, and M. Morari, “Move blocking strategies in receding horizon control,”Journal of Process Control, vol. 17, no. 6, pp. 563–570, Jul. 2007, doi: 10.1016/j.jprocont.2007.01.001.