using Plots
using JuMP
using Ipopt
using Interpolations
function river_crossing_direct_transcription()
wmax = 1.0 # One half of the width of the river.
Rmax = 3.0 # Can set opposite direction of flow with MINUS sign.
R(w) = Rmax*exp(-(w/wmax)^2) # Velocity of the river as a function of the distance from the center.
u(x,y) = R(y-sin(x))/sqrt(1+cos(x)^2) # x-component of the velocity of the flow.
v(x,y) = R(y-sin(x))*cos(x)/sqrt(1+cos(x)^2) # y-component of the velocity of the flow.
Vmax = 4.0 # Maximum velocity of the boat with respect to the mass of water.
V̇max = 100.0
θ̇max = 5
(xinitial,yinitial) = (0.0,-wmax) # Initial position of the boat.
(xfinal,yfinal) = (2*pi,wmax) # Final required position of the boat.
tfinal_0 = 5.0 # Initial guess for the final time.
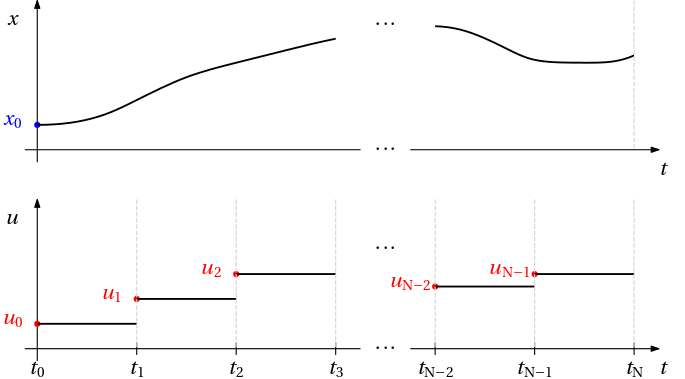
N = 50 # Number of time steps.
f₁(x,y,V,θ) = V*cos(θ) + u(x,y) # Dynamics of the boat.
f₂(x,y,V,θ) = V*sin(θ) + v(x,y)
model = Model(Ipopt.Optimizer)
set_silent(model)
@variable(model,tfinal>=0,start=tfinal_0) # Final time as an optimization variable.
h = tfinal/N # Time step.
@variable(model, x[1:N+1]) # N+1 values, because needed at the initial and final times.
@variable(model, y[1:N+1]) # N+1 values, because needed at the initial and final conditions.
@variable(model, 0.0 <= V[1:N] <= Vmax) # N values, because not needed at the final one.
@variable(model, θ[1:N]) # N values, because not needed at the final one.
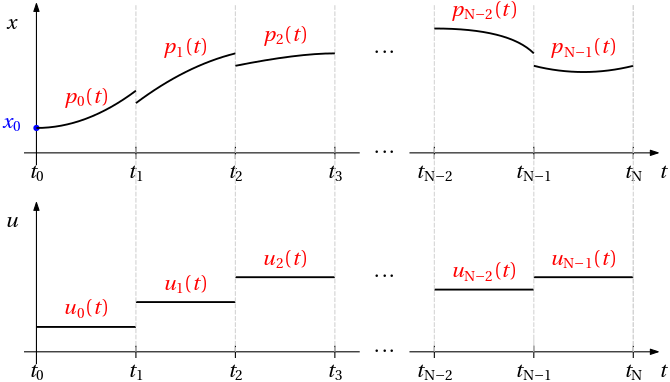
for i in 1:(N-1)
@constraint(model, x[i+1] == x[i] + h*(f₁(x[i],y[i],V[i],θ[i])+f₁(x[i+1],y[i+1],V[i+1],θ[i+1]))/2)
@constraint(model, y[i+1] == y[i] + h*(f₂(x[i],y[i],V[i],θ[i])+f₂(x[i+1],y[i+1],V[i+1],θ[i+1]))/2)
end
@constraint(model, x[N+1] == x[N] + h*(f₁(x[N],y[N],V[N],θ[N])+f₁(x[N+1],y[N+1],V[N],θ[N]))/2) # Over the last integration interval.
@constraint(model, y[N+1] == y[N] + h*(f₂(x[N],y[N],V[N],θ[N])+f₂(x[N+1],y[N+1],V[N],θ[N]))/2)
@expression(model, southern_bank[i=1:N+1],sin(x[i])-wmax)
@expression(model, northern_bank[i=1:N+1],sin(x[i])+wmax)
@constraint(model, [i=1:N+1], southern_bank[i] <= y[i]) # Constraints on the y coordinate.
@constraint(model, [i=1:N+1], northern_bank[i] >= y[i]) # Constraints on the y coordinate.
@constraint(model, [i=1:N-1], -V̇max*h <= V[i+1]-V[i]) # Constraints on the rate of change of the forward velocity.
@constraint(model, [i=1:N-1], V̇max*h >= V[i+1]-V[i]) # Constraints on the rate of change of the forward velocity.
@constraint(model, [i=1:N-1], -θ̇max*h <= θ[i+1]-θ[i]) # Constraints on the rate of change of the angular velocity.
@constraint(model, [i=1:N-1], θ̇max*h >= θ[i+1]-θ[i]) # Constraints on the rate of change of the angular velocity.
interp_linear_x = linear_interpolation([1, N+1], [xinitial, xfinal]) # Linear growth.
interp_linear_y = linear_interpolation([1, N+1], [yinitial, yfinal]) # Linear growth.
interp_linear_θ = linear_interpolation([1, N÷2, N], [1.0, 0.0, 1.0]) # V profile.
initial_guess_x = mapreduce(transpose, vcat, interp_linear_x.(1:N+1)) # Converting a vector of vectors to a matrix.
initial_guess_y = mapreduce(transpose, vcat, interp_linear_y.(1:N+1))
initial_guess_V = Vmax*ones(N) # Initial guess for the forward velocity: just max.
# initial_guess_θ = zero(initial_guess_V)
initial_guess_θ = mapreduce(transpose, vcat, interp_linear_θ.(1:N))
set_start_value.(x, initial_guess_x)
set_start_value.(y, initial_guess_y)
set_start_value.(V, initial_guess_V)
set_start_value.(θ, initial_guess_θ)
fix(x[1], xinitial) # Setting the initial positions.
fix(y[1], yinitial)
fix(x[N+1], xfinal) # Setting the final positions.
fix(y[N+1], yfinal)
@objective(model, Min, tfinal) # Cośt function for the minimum-time control.
optimize!(model)
println("""
termination_status = $(termination_status(model))
primal_status = $(primal_status(model))
objective_value = $(objective_value(model))
""")
gr(lw=2,label="",ls=:solid,markershape=:circle)
t = value(h)*(0:N)
p1 = plot(t[1:end-1],value.(V),ylabel="V",xlabel="t",seriestype=:steppost,ylims=(-0.1,1.1*Vmax))
p2 = plot(t[1:end-1],value.(θ),ylabel="θ",xlabel="t",seriestype=:steppost)
pA = plot(p1,p2,layout=(2,1))
pB = plot(value.(x),value.(y),ylabel="y",xlabel="x")
xrange = 0:0.01:2*pi
ynorth = sin.(xrange) .- wmax
ysouth = sin.(xrange) .+ wmax
plot!(xrange,ynorth)
plot!(xrange,ysouth)
return pA,pB
end
pA,pB = river_crossing_direct_transcription()
plot(pB)